
JSTOR Labs recently announced a new way to search called Text Analyzer (https://www.jstor.org/analyze/). You can upload a document such as a draft paper or another article that you found on JSTOR and the Text Analyzer generates a list of research articles and subject terms to help you find new sources. We have seen similar technology in brief checking tools offered by Westlaw and Lexis, but this is the first tool we’ve seen that applies this kind of AI in a scholarly setting.

How does it work? After you upload a document, the tool analyzes the text for key topics and phrases. It will identify certain keywords as “prioritized terms” and then look for similar content in JSTOR. The Text Analyzer allows you to edit the list of “prioritized terms” by adding or removing words or phrases or by adjusting their importance.
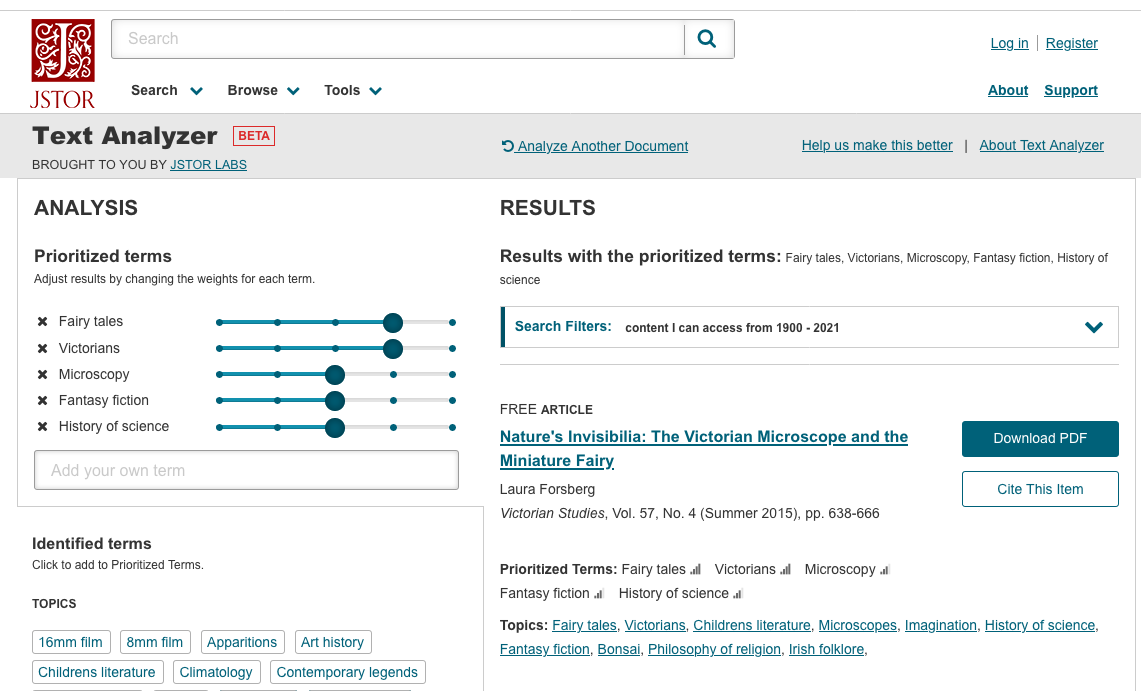
While I imagine that MS Word or PDF files would be the most common types of documents uploaded, the Text Analyzer accepts the following types of files: csv, doc, docx, gif, htm, html, jpg, jpeg, json, pdf, png, pptx, rtf, tif (tiff), txt, xlsx.
JSTOR offers a few other tips and suggestions for how the tool can be useful:
- If you access Text Analyzer using your phone, a camera icon will appear — use it to take a picture of any page of text and search with that.
- To run Text Analyzer on the text of a webpage — whether it’s a Google Doc or a NY Times article — drag and drop or paste the URL into the search box.
- Get creative with the kinds of documents you search with: try your class syllabus, the webpage of a news article, or the first paragraph or outline of a paper you’re writing.
- Try searching with non-English-language content if you have it — Text Analyzer can help you find you find English-language content about the same topics in JSTOR.
Note that the JSTOR Text Analyzer tool is still in beta, but it shows potential as an additional tool in your research toolbox.
